Tavloid: towards Simple Verifiable Spreadsheets and Databases
Author: Matteo Campanelli
Date: October 2022 (original publishing); May 2024 (republishing)

I originally wrote this post while working at Protocol Labs in the cryptonet team. I have since left cryptonet and Protocol Labs. Since it is not unclear for how long that post will be online, I’m reposting it here on binarywhales.com. The overwhelming majority of the post is the same as the original.
This post presents some ideas we have been working on at cryptonet to obtain simple verifiable databases.
If you need more context on the setting, please see this page. As a refresher on the setting though:
- assume there is a public short commitment to a spreadsheet or a large database;
- we want to support queries on these data so that it is fast to cryptographically guarantee that the query response was correct given a short certificate for the query.
We generically refer to this setting as verifiable tables.
What’s Tavloid?
Tavloid is a simple approach to verifiable tables that mainly strives for:
- Concrete efficiency
- Simplicity: based on few basic components, easy to understand as possible, fast to implement.
There is a vast literature on the problem, but much of it focuses on asymptotic behavior using sophisticated (but complex) data structures; often it does not achieve the practical efficiency (especially in proof size) we may hope for.
In addition to being efficient and simple, Tavloid aims at:
- Being “SNARK later” (rather than “SNARK first”): general-purpose SNARKs a sledgehammer-type solution to the problem. Tavloid strives for more targeted solutions and that do not require compiling to a special representation, such as a circuit.
- Being extensible: while what we describe here supports a very basic application setting, it is possible to make it more powerful without sacrificing modularity. For this reason Tavloid strives for the use of algebraically-flavored commitments (think: KZG-ish yes; Merkle-tree-ish no) which can connect easily with other proof systems (not necessarily general-purpose).
What it can do: queries and efficiency
What it supports: Tavloid supports simple SELECT and (inner) JOIN queries in databases. It is especially suited for SELECT queries for membership of categorical data or testing for small ranges. JOINs in Tavloid are also efficient on categorical data. (What do I mean by “categorical”?See below for an example, but in general I will refer to “categorical queries” as “queries on categorical data” and by “categorical data” I will mean data whose attributes are something like enumerations in some programming languages)
Some efficiency features are:
- constant-size commitments to a database (32 bytes).
- proof sizes independent of table size or the number of rows in the query response. Proof size grows linearly in , which depends on the categorical membership query (in the example below because we are checking 3 categories, the countries)
- verification consisting of roughly a linear number of group operations in the response size and a number of pairings that is linear in .
As an example query and its costs consider:
/* Users from countries in Fenno-Scandinavia (as an example of "categorical membership")*/
SELECT * FROM Users WHERE Country in ("SE", "NO", "FI")Let us assume a response with rows and columns, then:
- a proof for the query would be group elements in a pairing setting (of which 3 in ), slightly less than 1.5 kilobyte. See bottom of post for a breakdown.
- verification time would be in the ballpark of (less than) 100ms.
Tavloid can be adapted to support different tradeoffs in commitment size, verification time and proof size. For instance, the proof size above can be cut by at one half if traded for a larger commitment.
These ideas easily support spreadsheets (i.e., a setting without JOINs) as a special case. It currently supports databases that are static or whose updates are performed publicly, i.e., all users need to update the commitment to the database when that occurs, or such update need to be proved. One of our current goals is to optimize more types of updates (notice that updates such as adding a whole column (set of columns) are already supported easily since they mostly consist of adding one more commitment).
What’s next
For now Tavloid mostly supports filtering operations of sort (SELECTs and JOINs), and of a specific type. Other things we are looking at:
- other filtering criteria, e.g. range queries based on linear combinations of data.
- Aggregating/mapping/reducing data, i.e. producing a (potentially compact) results from operations on the data. (NB: some simple aggregation such as SUMs are already easily supported.)
Is there anything novel here?
A fair amount of our work got inspired by / independently rediscovered / borrowed from approaches and constructions out there, in particular these two papers (here and here). Reverse-lookup commitments have been used before in some form or the other; applying some type of commitment to “columns as vectors”, mostly Merkle trees, is folklore.
What we think is new or promising:
- Our stress on simplicity: our cryptographic primitives are as plain as possible and so are the underlying data structures—e.g. we do not need to keep any special tree structure balanced; we just use vectors and sets.
- We purposefully use very modern forms of vector commitments which:
- have aggregation and subvector opening. These features do the heavy lifting of reducing proof size—and they do it simply.
- can be easily linked with SNARKs for future extensions (see, e.g., the perspective in Legosnark and Caulk).
- are homomorphic. We are currently working on a few gadgets for proving properties on columns that exploit this property.
- We exploit specific properties of our setting, which allows for example not to make black box use of the union capabilities of accumulators in literature.
How it works in a nutshell
The main idea behind Tavloid is roughly to:
- process each column of data tables by two authenticated data structures (see below)
- using and combining the openings of these authenticated data structures to show the filter that happens in WHERE and ON clauses (in SELECTs and JOINs respectively).
Combining the openings is quite simple for SELECTs and a little bit more complicated for JOINs. In this post we try and give the bulk of the intuition. We stress that we assume that the processing stage is performed honestly.
The two authenticated data structures we use are:
- the, by now standard, vector commitments (with subvector openings and aggregation properties). Intuitively, we use these to verify whether claimed values in the response are really in the claimed rows/indices.
- another authenticated data structure, less standard, which we call “reverse lookup commitment”. You can think of it as a cousin of vector commitments that is i) more key-value flavored, and ii) where the “value” part is a (compressed) set. Intuitively, we use these to prove whether the claimed rows/indices are the ones we should really be looking at.
In our figures we depict these two primitives through the following:

We now go in a little bit more detail considering spreadsheets as a simpler setting to illustrate our construction.
Warm-up: A solution for spreadsheets
Let us first consider a spreadsheet—which we can think of as a collection of (parallel) columns—and the task of queries that just filter data. Although we talk about spreadsheets we will use the language of SQL queries not to introduce other notations.
Breaking down a query response
Here we consider queries of the type “SELECT columns WHERE criteria_on_columns”. Look at the “Fennoscandian countries” example from before. A response to it will be a subset of rows with the respective column values. Once received a response, we can break down what a client should verify int two sub-questions:
- Are the row indices the ones for the requested criteria? (in this case, rows referring to countries in the Fennoscandian peninsula—Finland, Sweden, Norway)
- Are all the values from those specific rows the actually from the committed spreadsheet?
To connect these sub-questions to the authenticated data structures above: vector commitments take care of question (2); reverse lookup commitments take care of question (1).
Vector commitments: from row indices to values
Given a set of row indices we are claiming in our response, it is easy to prove values in vector commitments. What we do is straightforwardly committing to each column:
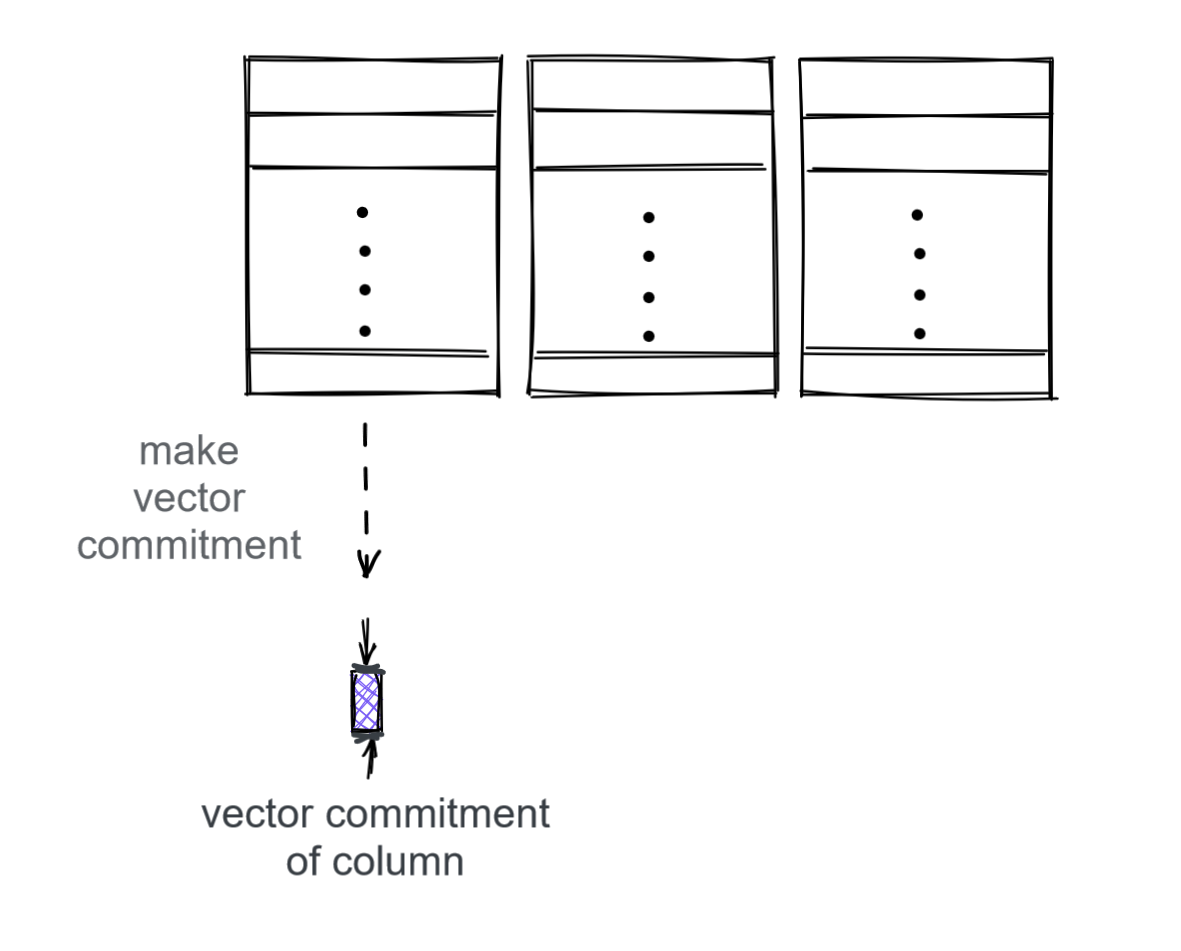
We can instantiate vector commitment in several ways in order to obtain our required properties, for example through the constructions in Pointproofs or the Muppets paper.
But why aren’t vector commitments enough? For example because a server could give us all the correct row values, but not for all Fenno-Scandianavian countries. We need to do more.
Reverse lookup commitments: from value criteria to rows
How can the client obtain the guarantee it is seeing all the rows referring to Fennoscandian countries? We use an authenticated data structure for key-value maps that specifically:
- takes as input a possible column value as key (e.g., “NO”)
- returns a certificate for a set of rows—the value the key maps to—containing that particular column value (e.g., all the row indices with “NO” as country)
We call such a structure a “reverse lookup” commitment since it performs a lookup from values to (sets of) indices.
But not quite efficient yet—two more challenges to solve
The primitive described above is not exactly what we need yet since we still need to solve two problems.
One problem is (at the very high level): if we certify a “set of rows”, this set may be something too large to handle for commitment/verification. We should then use a compressed version of sets, this could be a hash or an accumulator.
A second challenge is that we want to deal not only with single values but with multiple criteria/selections at the same time (e.g., we want to select not only for one country but for multiple ones at the same time). In order to support this, we compress the set through specific accumulators that also support small certificates for set union queries. In the example above, the union will be “the rows belong to all of the Fennoscandian countries”. Notice that for categorical queries, this proof will turn out to be empty because we are dealing with disjoint union (see also details below)
Below is a drawing showing an example of how to commit to a column (in this case the column “Countries”) into a reverse lookup commitment.
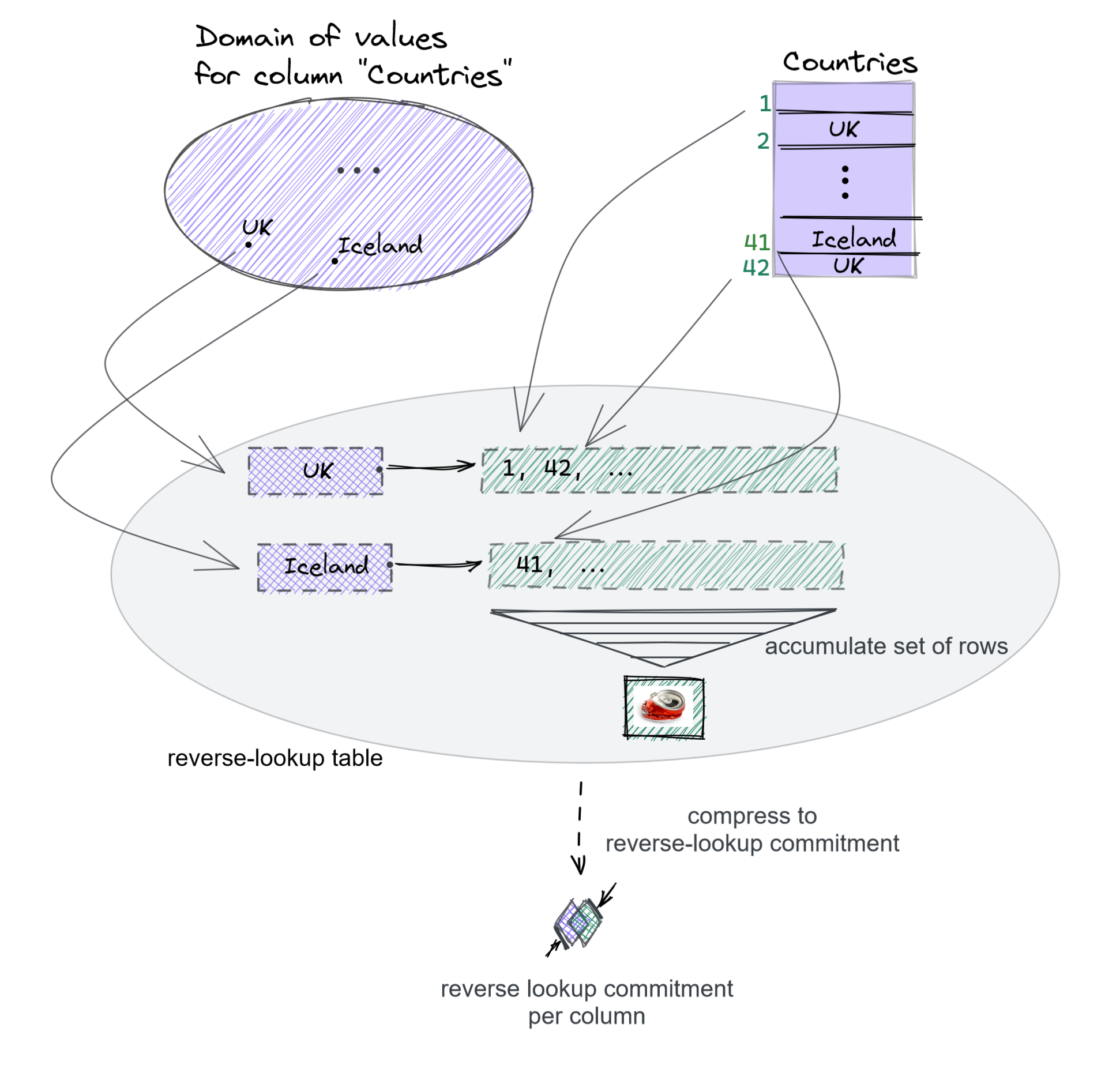
But how do we instantiate this primitive? We obtain it by modifying existing techniques. In order to obtain the “outer” key-value commitment, we can use any vector commitment and use a hash function (or some other predetermined mapping) to go from values to indices supported by the vector commitment. In order to accumulate the set into something that supports disjoint unions (and, later, also intersections), we can use techniques based on bilinear maps. We can for example use the KZG polynomial commitment on the characteristic polynomial of the set as shown in Papamanthou et al. To verify a disjoint union we can specialize the techniques from this paper to the case of disjoint union. This involves providing incremental products in the group (plus more) and checking these products on pairings.
NB: There are several natural optimizations that we do apply but that we do not discuss in this introductory post. This is just a very high-altitude view of the protocol. An example of such optimizations is: compressing all authenticated data structures into one single (vector) commitment to save on parameters’ size.
Putting it all together
So, more explicitly, how does a client verify a response? A general template using the language of our example follows. We’ll fix the inefficiency by using aggregation properties
- it receives a set of rows and related values (the response)
- it receives a vector commitment opening for each of the columns. These openings refer to a set of rows R. These can be verified straightforwardly as usual.
- it receives a reverse lookup proof for each country value and the related compressed accumulator.
- To verify the reverse lookup proofs, the client checks:
- reverse lookups: it checks each of the reverse lookup proof for each of the accumulators
- their intersection: it produces a compressed set for the set of rows R and it checks that this consists of the union of the other accumulators.
- To verify the reverse lookup proofs, the client checks:
To make the template above efficient we rely on aggregation and subvector properties of the vector commitments so that the client can receive a single proof (this is also true for the proofs in the reverse lookup commitment).
From spreadsheets to databases
The solution described so far is the bulk of our scheme for databases. If in a spreadsheet we apply the procedures in Figures 2 and 3 per column, in a database we will apply it to each column in every table. To further adapt our scheme, though, we need to replace row indices and show how to deal with (inner) JOINs.
From indices to primary key
As a first step to adapt our solution to the database setting we replace the sets of rows in the reverse lookup commitments. Instead of indices, we will use primary keys from the related table.
Supporting JOINs
Our solution already contains the main ingredients to support efficient JOINs. What we need to rely as extra is intersection proof features of the accumulated sets in the reverse lookup commitments. For example, let us look at this query:
/* All posts from filtered users */
SELECT * FROM Users JOIN Posts
ON Users.id = Posts.uid
WHERE Users.Country in ("SE", "FI", "NO")In order to handle the above we let the server provide two accumulated sets of rows: one corresponding to the rows in the Posts table (all rows), another corresponding to the filtered-by-country rows in the Country table. In addition to those, it provides an intersection proof for the two showing that results in the right final set of rows. This increases communication by a constant number of group elements.
Acknowledgements and Contacts
Thanks to Nicola Greco, Anca Nitulescu, Nicolas Gally (who were at cryptonet at the time this post was written) and Mahak Pancholi (Aarhus University) for helpful discussions on these constructions.
For any questions or comments: binarywhalesinternaryseas@gmail.com
Appendix
Breakdown of Proof Size
This is a special case and can be generalized: it assumes one multicategorical on categories WHERE and one JOIN.
Below and are group element sizes of the respective groups in the bilinear setting.
For a SELECT with a single JOIN with a categorical query of size (see examples):
- // column vector commitments, one per column
- // reverse lookup commitment (in this case it is for one column only)
- // values (compressed sets) in reverse lookups
- // proofs for disjoint union
- // intersection proof for JOIN
- // Single aggregated vector commitment proof